MCP server by spped2000
Tavily MCP Agent สำหรับ Google ADK
ระบบค้นหาและวิเคราะห์ข่าวที่ใช้ Google ADK (Agent Development Kit) ร่วมกับ Tavily MCP (Model Context Protocol) เพื่อรวบรวมข้อมูลข่าวจากหลายเว็บไซต์อย่างครบถ้วนและแม่นยำ
เครื่องมือที่ใช้พัฒนา

ระบบพัฒนาโดยใช้เครื่องมือต่างๆ ดังแสดงในภาพ ประกอบด้วย Google ADK, Tavily MCP, Gemini API และเครื่องมืออื่นๆ ที่จำเป็นสำหรับการทำงานของ Agent
ความสามารถหลัก
การค้นหาแบบหลายเครื่องมือ
- tavily-search: ค้นหาบทความและเนื้อหาที่เกี่ยวข้อง
- tavily-extract: ดึงเนื้อหาฉบับเต็มจาก URL ที่กำหนด
- tavily-map: สำรวจโครงสร้างและหน้าต่างๆ ของเว็บไซต์
- tavily-crawl: รวบรวมข้อมูลอย่างละเอียดและครอบคลุม
ฟีเจอร์พิเศษ
- การค้นหาแบบขอบขนาน: ค้นหาหลายเว็บไซต์พร้อมกันเพื่อความเร็ว
- การดึงข้อมูลแบบครบถ้วน: ใช้การค้นหาร่วมกับการดึงเนื้อหาเต็มเพื่อความแม่นยำสูงสุด
- เนื้อหาฉบับสมบูรณ์: ได้รับบทความเต็ม ไม่ใช่เพียงส่วนย่อย
- การวิเคราะห์ข้ามแหล่ง: รวบรวมและเปรียบเทียบข้อมูลจากหลายแหล่ง
- การเลือกเครื่องมืออัจฉริยะ: เลือกใช้เครื่องมือที่เหมาะสมกับงานแต่ละประเภทโดยอัตโนมัติ
รองรับภาษาไทยและภาษาอังกฤษ
- รองรับคำค้นหาภาษาไทยและภาษาอังกฤษ
- สามารถระบุเว็บไซต์เป้าหมายได้ (เช่น thairath.co.th, bbc.com/thai)
- ปรับแต่งสำหรับการค้นหาข่าวโดยเฉพาะ
- แสดงแหล่งที่มาของข้อมูลอย่างชัดเจน
ความต้องการของระบบ
ก่อนเริ่มใช้งาน กรุณาติดตั้งโปรแกรมต่อไปนี้:
- Python 3.10 หรือสูงกว่า
- Node.js และ npm (สำหรับ Tavily MCP server)
- Git (สำหรับจัดการ version control)
การติดตั้ง
1. Clone Repository
git clone https://github.com/spped2000/tavily-mcp-agent.git
cd tavily-mcp-agent
2. สร้าง Virtual Environment
Windows:
python -m venv .venv
.venv\Scripts\activate
macOS/Linux:
python3 -m venv .venv
source .venv/bin/activate
3. ติดตั้ง Dependencies
pip install google-adk
4. ตั้งค่า Environment Variables
สร้างไฟล์ .env ในโฟลเดอร์หลัก:
TAVILY_API_KEY=your_tavily_api_key_here
วิธีการขอ API key:
- เข้าไปที่ https://tavily.com
- สมัครสมาชิก
- รับ API key จาก dashboard
โครงสร้างโปรเจ็กต์
tavily-mcp-agent/
├── my_agent/
│ ├── __init__.py
│ ├── agent.py # ไฟล์กำหนดค่าหลัก
│ └── .env # Environment variables ของ agent
├── .env # Environment variables หลัก
├── .gitignore # กฎการ ignore ไฟล์ใน git
└── README.md # ไฟล์นี้
กลยุทธ์การทำงาน
ระบบใช้กลยุทธ์หลายขั้นตอนเพื่อให้ได้ข้อมูลที่ครบถ้วนและแม่นยำที่สุด:
ขั้นที่ 1: การค้นหาแบบขนาน
- ค้นหาแต่ละเว็บไซต์พร้อมกัน
- ใช้พารามิเตอร์ที่เหมาะสม:
include_answer,include_raw_content,max_results: 10 - กำหนด
search_depth: "advanced"เพื่อผลลัพธ์ที่ละเอียด - สำหรับข่าว: ใช้
topic: "news"และtime_range: "week"
ขั้นที่ 2: การดึงเนื้อหาเต็ม
- เลือกบทความสำคัญจากแต่ละเว็บไซต์
- ใช้
tavily-extractเพื่อดึงเนื้อหาฉบับเต็ม - ไม่พึ่งพาเพียงส่วนย่อยจากผลการค้นหา
- รับประกันความแม่นยำและบริบทที่สมบูรณ์
ขั้นที่ 3: การสำรวจโครงสร้าง (ทางเลือก)
- สำหรับการค้นหาที่ต้องการความครอบคลุม
- ใช้
tavily-mapเพื่อค้นหาหน้าข่าวทั้งหมด - สำรวจโครงสร้างเว็บไซต์อย่างชาญฉลาด
ขั้นที่ 4: การรวบรวมข้อมูลแบบละเอียด (ทางเลือก)
- สำหรับคำขอที่ต้องการข้อมูลครบถ้วนมาก
- ใช้
tavily-crawlเพื่อรวบรวมข้อมูลอย่างเป็นระบบ - มีการค้นพบหน้าที่เกี่ยวข้องอย่างชาญฉลาด
การใช้งาน
เริ่มต้นระบบ
cd my_agent
adk web
เปิดเบราว์เซอร์ไปที่ URL ที่แสดง (โดยปกติคือ http://localhost:8000)
ตัวอย่างคำถาม
การค้นหาพื้นฐาน:
ค้นหาข่าวล่าสุดเกี่ยวกับปัญญาประดิษฐ์
การค้นหาภาษาไทย:
สรุปข่าวน้ำท่วมประเทศไทยล่าสุด
การค้นหาจากหลายเว็บไซต์ (แนะนำสำหรับผลลัพธ์ที่ดีที่สุด):
สรุปข่าวน้ำท่วมประเทศไทยล่าสุด จาก https://www.thairath.co.th/ และ https://www.bbc.com/thai
ระบบจะ:
- แยกชื่อโดเมน:
["thairath.co.th", "bbc.com"] - ค้นหาทั้งสองเว็บไซต์แบบขนาน
- ดึงเนื้อหาเต็มจากบทความสำคัญ
- เปรียบเทียบและสังเคราะห์ข้อมูล
- แสดงผลลัพธ์ที่จัดกลุ่มตามแหล่งที่มา
การวิเคราะห์แบบครอบคลุม:
ค้นหาข้อมูลทั้งหมดเกี่ยวกับการเปลี่ยนแปลงสภาพภูมิอากาศจาก bbc.com
ระบบอาจใช้:
tavily-searchเพื่อหาบทความที่เกี่ยวข้องtavily-mapเพื่อค้นหาหน้าที่เกี่ยวข้องทั้งหมดtavily-extractเพื่อดึงเนื้อหาเต็มtavily-crawlเพื่อสำรวจอย่างละเอียด (ถ้าจำเป็น)
รูปแบบการตอบ
ระบบจะแสดงผลลัพธ์ในรูปแบบที่จัดระเบียบ:
[สรุปภาพรวม - สังเคราะห์ข้อมูลจากทุกแหล่ง]
## ข้อมูลจากแหล่งต่างๆ
### จาก thairath.co.th:
1. **[ชื่อบทความ]**
- URL: https://thairath.co.th/article/...
- วันที่: [วันที่]
- สาระสำคัญ: [ประเด็นสำคัญ]
- รายละเอียด: [รายละเอียดที่ดึงมา]
2. **[ชื่อบทความ 2]**
- ...
### จาก bbc.com/thai:
1. **[ชื่อบทความ]**
- URL: https://bbc.com/thai/article/...
- วันที่: [วันที่]
- สาระสำคัญ: [ประเด็นสำคัญ]
- รายละเอียด: [รายละเอียดที่ดึงมา]
## สรุปรวม
[การวิเคราะห์เปรียบเทียบ รูปแบบ และข้อค้นพบสำคัญ]
## ลิงก์ทั้งหมด
[รายการ URL ทั้งหมดที่จัดกลุ่มตามแหล่งที่มา]
เครื่องมือและพารามิเตอร์
ระบบมีเครื่องมือทั้งหมด 4 ตัวจาก Tavily MCP:
1. tavily-search
ค้นหาบทความและเนื้อหาที่เกี่ยวข้อง
พารามิเตอร์สำคัญ:
| พารามิเตอร์ | ประเภท | คำอธิบาย | ค่าเริ่มต้น |
|-----------|------|----------|------------|
| query | string | คำค้นหา (จำเป็น) | จากผู้ใช้ |
| search_depth | string | "basic" หรือ "advanced" | "advanced" |
| topic | string | "general" หรือ "news" | "news" (สำหรับข่าว) |
| include_answer | boolean | รวมสรุปจาก AI | true |
| include_raw_content | boolean | รวมเนื้อหาต้นฉบับ | true |
| max_results | number | จำนวนผลลัพธ์สูงสุด (5-20) | 10 |
| include_domains | array | ระบุเว็บไซต์เฉพาะ | ดึงอัตโนมัติ |
| time_range | string | "day", "week", "month", "year" | "week" (สำหรับข่าว) |
2. tavily-extract
ดึงเนื้อหาฉบับเต็มจาก URL เฉพาะ
พารามิเตอร์:
urls: รายการ URL ที่ต้องการดึงข้อมูลextract_text: true (ดึงข้อความ)extract_links: true (ดึงลิงก์)extract_images: true (ดึงรูปภาพ)
ใช้เมื่อ: หลังจากค้นหาเพื่อดึงเนื้อหาบทความเต็ม
3. tavily-map
ค้นพบโครงสร้างและหน้าต่างๆ ของเว็บไซต์
พารามิเตอร์:
url: URL หลักที่จะสำรวจmax_depth: ความลึกในการสำรวจ (ค่าเริ่มต้น: 2)max_pages: จำนวนหน้าสูงสุด (ค่าเริ่มต้น: 50)
ใช้เมื่อ: ต้องการสำรวจเว็บไซต์อย่างครอบคลุม
4. tavily-crawl
รวบรวมข้อมูลอย่างละเอียดพร้อมการค้นพบอัจฉริยะ
พารามิเตอร์:
url: URL หลักที่จะรวบรวมข้อมูลmax_depth: ความลึกในการรวบรวม (ค่าเริ่มต้น: 2)max_pages: จำนวนหน้าสูงสุด (ค่าเริ่มต้น: 30)extract: true (ดึงเนื้อหาขณะรวบรวม)intelligent_discovery: true (การค้นพบด้วย AI)
ใช้เมื่อ: ต้องการข้อมูลทั้งหมดหรือการวิเคราะห์ที่ครบถ้วน
การปรับแต่ง
แก้ไขพฤติกรรมของ Agent
แก้ไขไฟล์ my_agent/agent.py:
root_agent = Agent(
model="gemini-3-pro-preview", # เปลี่ยน model ที่นี่
name="tavily_agent",
instruction="...", # แก้ไข instructions ที่นี่
tools=[...]
)
เปลี่ยน Model
Model ที่ใช้ได้จาก Google ADK:
gemini-3-pro-preview(ปัจจุบัน)gemini-2.5-progemini-2.0-flash
ปรับพารามิเตอร์การค้นหา
แก้ไข instructions ในไฟล์ agent.py เพื่อเปลี่ยน:
- พารามิเตอร์การค้นหาเริ่มต้น
- รูปแบบการตอบ
- พฤติกรรมเฉพาะภาษา
- กฎการกรองโดเมน
การแก้ปัญหา
ปัญหาที่พบบ่อย
1. ไม่พบ TAVILY_API_KEY
- ตรวจสอบว่าไฟล์
.envมีอยู่และมี API key ที่ถูกต้อง - ตรวจสอบว่า virtual environment ถูก activate แล้ว
2. ไม่พบคำสั่ง npx
- ติดตั้ง Node.js จาก https://nodejs.org
- ตรวจสอบว่า npm อยู่ใน system PATH
3. Connection timeout
- ตรวจสอบการเชื่อมต่ออินเทอร์เน็ต
- ตรวจสอบว่า API key ถูกต้อง
- ลองเพิ่ม timeout ในไฟล์
agent.py(ปัจจุบันคือ 30 วินาที)
4. Agent ไม่แสดงแหล่งอ้างอิง
- Restart ADK web server
- ตรวจสอบว่าไฟล์ agent.py ถูก update แล้ว
- ตรวจสอบ console สำหรับข้อความ error
โหมด Debug
เปิดใช้งาน debug logging:
adk web --debug
ตัวอย่างการใช้งาน
ภาพตัวอย่างการทำงานของระบบ
ด้านล่างนี้เป็นภาพตัวอย่างการใช้งาน Agent ในการค้นหาและวิเคราะห์ข่าวจากหลายเว็บไซต์
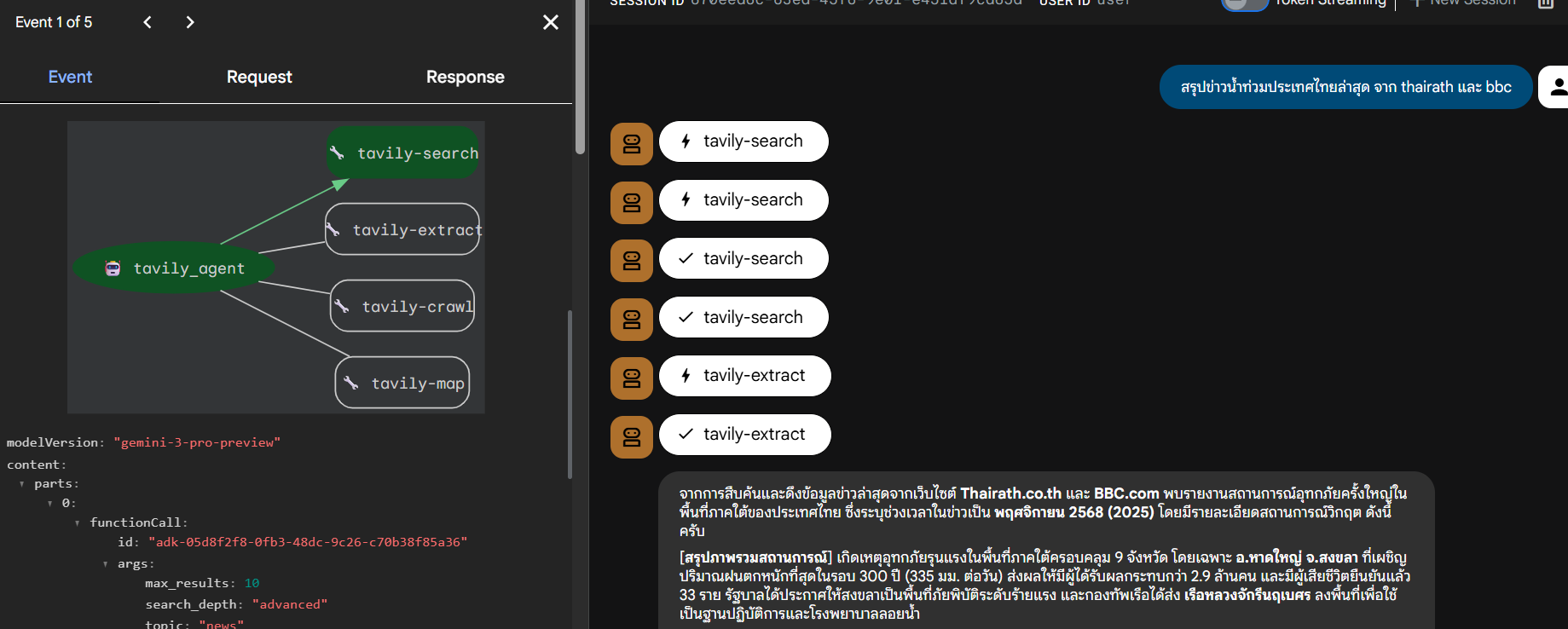
ตัวอย่างหน้าจอการเริ่มต้นใช้งานระบบ
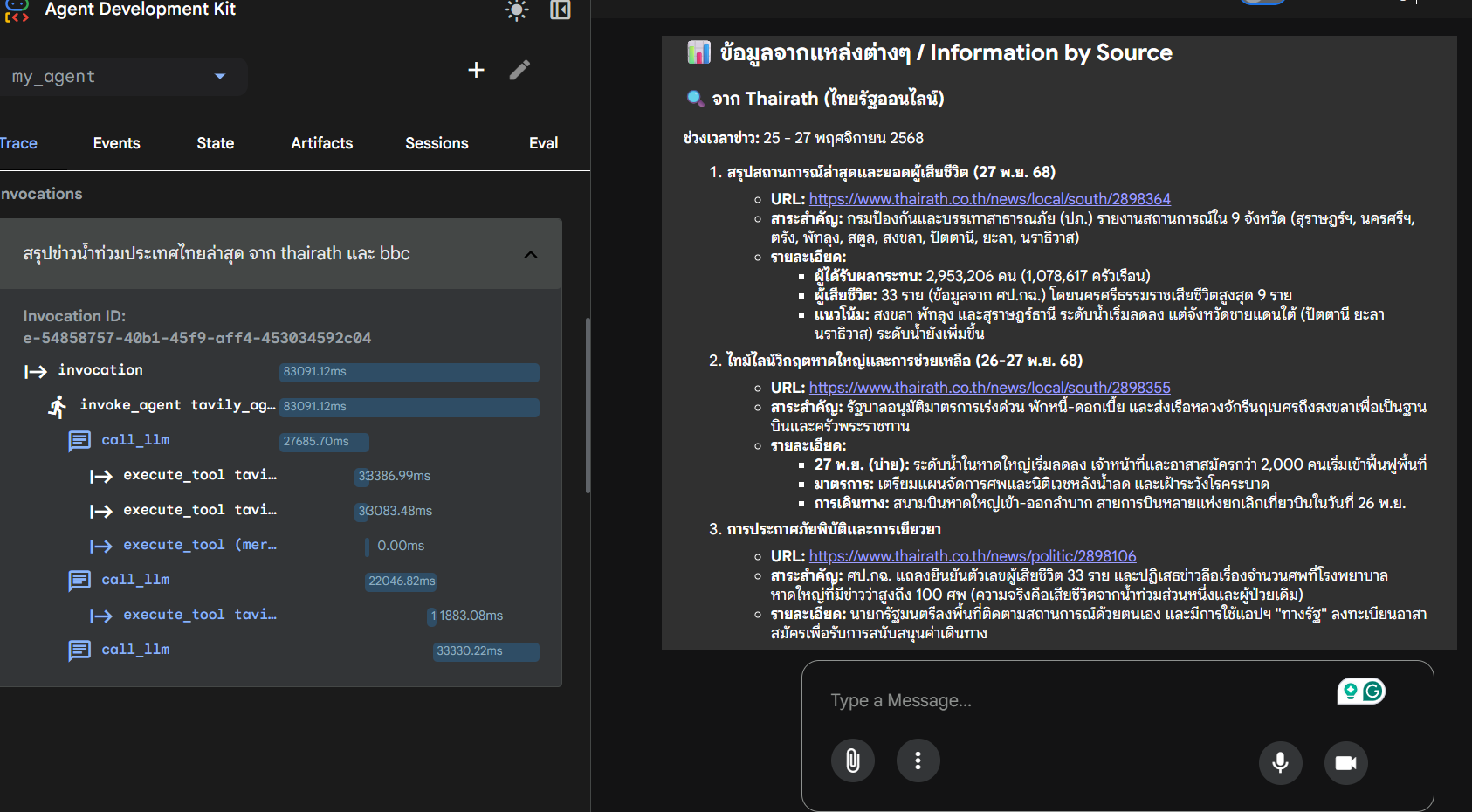
ตัวอย่างการค้นหาข่าวจากหลายเว็บไซต์
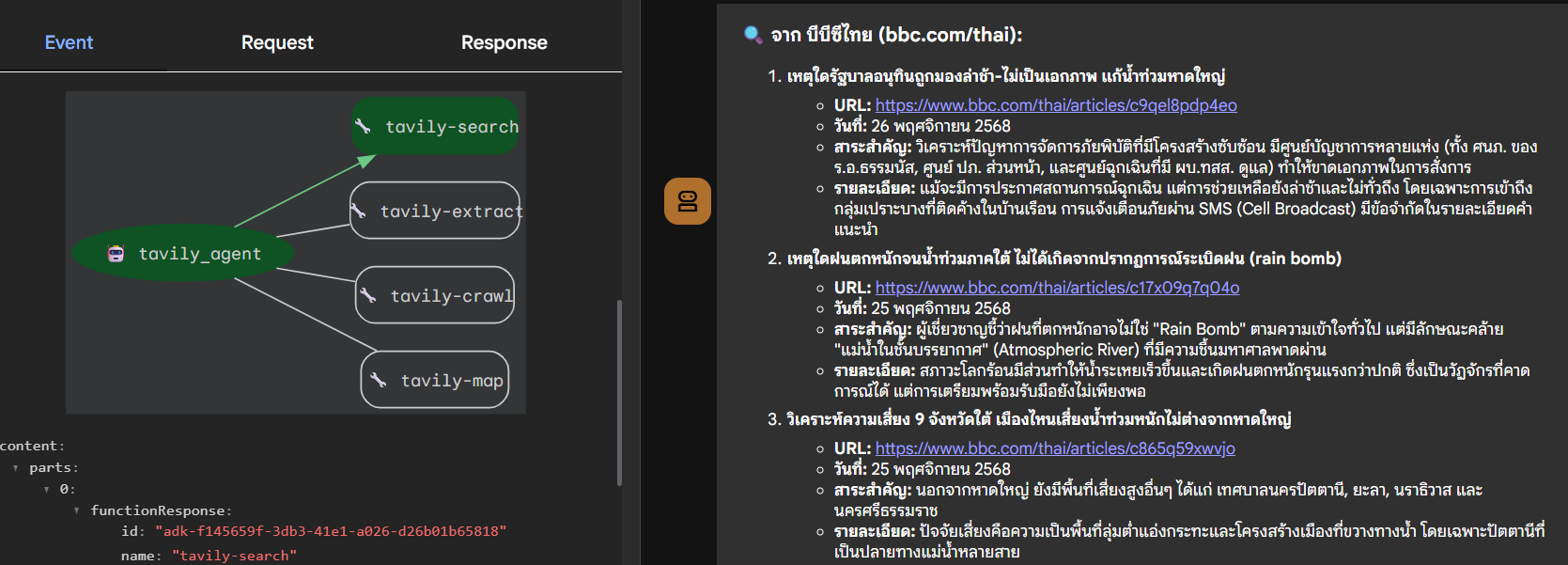
แสดงการใช้งาน tavily-search และ tavily-extract

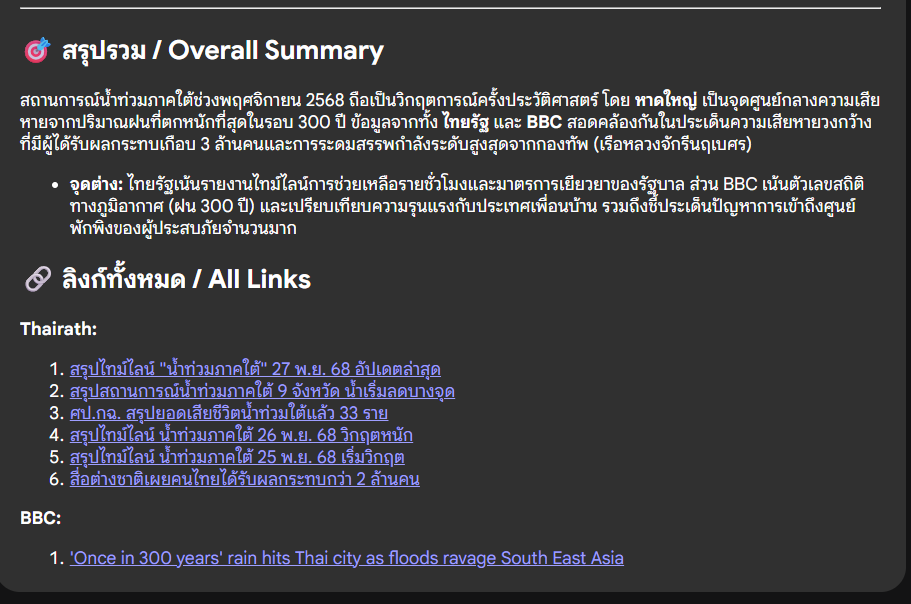
ตัวอย่างการแสดงผลลัพธ์ที่จัดกลุ่มตามแหล่งที่มา
ตัวอย่างการสรุปข้อมูลจากหลายแหล่งพร้อมรายละเอียดเต็ม
การพัฒนา
โครงสร้างโค้ด
- agent.py: การกำหนดค่า agent หลักพร้อม instructions และ tools
- MCPToolset: จัดการการเชื่อมต่อ MCP กับ Tavily server
- StdioConnectionParams: กำหนดค่าการเชื่อมต่อ stdio สำหรับ MCP
การมีส่วนร่วม
ยินดีรับการมีส่วนร่วม กรุณาส่ง Pull Request
ขั้นตอนการพัฒนา
- Fork repository
- สร้าง feature branch (
git checkout -b feature/amazing-feature) - Commit การเปลี่ยนแปลง (
git commit -m 'Add amazing feature') - Push ไปยัง branch (
git push origin feature/amazing-feature) - เปิด Pull Request
แหล่งข้อมูล
ใบอนุญาต
MIT License
ข้อมูลเพิ่มเติม
- สำหรับปัญหาและคำถาม: เปิด issue ใน repository นี้
- ตรวจสอบ เอกสาร Google ADK
- เยี่ยมชม Tavily Support
หมายเหตุ: ระบบต้องการ API key ที่ถูกต้องสำหรับทั้ง Google Cloud (สำหรับ Gemini models) และ Tavily (สำหรับการค้นหา) กรุณาตรวจสอบ API quotas และการตั้งค่าการเรียกเก็บเงินสำหรับการใช้งานจริง